


Fast jeder hat schon mal von Cookies gehört. Aber nur wenige wissen, welche Bedeutung sie für Webseiten haben. Webseiten werden in HTML-Code beschrieben und über HTTP übertragen. HTTP ist ein zustandsloses Protokoll. D.h. jede Anfrage steht, ohne Hilfsmittel, für eine eigenständige Abfrage von Daten. Im Klartext, es wäre nicht möglich eine Sitzung oder andere Dinge auf einer Webseite bzw. auf dem Webserver zu erkennen. Also hat man sich zu Beginn des Webzeitalters für kleine Textdateien entschieden, die wir heute Cookies nennen. Cookies können alles mögliche enthalten. Allerdings dürfen diese Cookies bestimmte Grenzen nicht über- bzw. unterschreiten, wie z.B. die Dateigröße (ca. 4096B – 4MB) oder die Anzahl von Cookies pro Domain (min. 50 Stück). Diese Regeln sind in der RFC 6265 festgehalten und jeder Browserhersteller sollte sich an diese minimal Regeln halten.
Sind Cookies gefährlich?
Ein Cookie ist ein Konstrukt, welche es Webentwicklern ermöglicht, Content zu kreieren der auf den jeweiligen Benutzer zugeschnitten ist. Das bedeutet, pauschal kann man nicht sagen, dass Cookies schlecht oder gut sind. Der Umgang mit diesem Werkzeug ist entscheidend, genauso wie bei einem Hammer. Jeder der diese Informationen behandelt, ist sozusagen dafür verantwortlich wie mit diesen Informationen umgegangen werden könnte. Es ist also auch entscheidend wie die Browserhersteller mit diesen Informationen umgehen. Lässt mein Browser beispielsweise zu, dass Cookies von fremden Webseiten ausgelesen werden können, ist dies eine schwere Lücke.
Anders sieht es beispielsweise aus, wenn ich einen großen Webservice benutze, um meine Besucher zu zählen. Um diese Zählung zu ermöglichen, muss ich als Dienstanbieter in der Lage sein bekannte Benutzer zu erkennen. Schließlich will ich nicht wissen, wie oft meine Seite angeschaut wird. Ich möchte wissen, wie viele Personen mich besucht haben. In den Anfängen des Webs gab es nur stupide Zähler die alles gezählt haben, nur nicht die Benutzer. Google hat dann erkannt, dass sie Dienste benötigen um Benutzer zu klassifizieren. Also schuf Google ein Werbenetzwerk und Webseiten-Tools um die Webseitenbetreiber an sie zu binden. Schließlich will doch “jeder” Geld verdienen und wenn das mit Google so einfach ist, na dann bau ich mir halt den Code von denen in meine Webseite ein. Mittlerweile ist Google so mächtig, dass es eigentlich das ganze Internet in der Hand hat. Fragt man einen Webseitenbetreiber nach Ad-Words oder Analytics wird dieser bestätigen, das er diese Dienste kennt und auch schon mal benutzt hat.
Tracking ohne Cookies
Google ist sozusagen in der Lage, mit dem verteilten Code, in Echtzeit zu erkennen, welche Interessen und Themen gerade bei den Nutzern so gefragt sind. Google hat folglich die Basistechniken in der Hand und die Techniken welche fehlen, werden eingekauft.
Meine Seite war hier schon etwas sonderbar, denn ich habe das Google-Tracking nicht aktiv eingebunden. Anfangs war mir der Aufwand zu hoch, die entsprechenden und nervigen Popups auf meiner Seite zu implementieren. Dennoch könnte Google anhand der eingebundenen Schriften oder Skript-Bibliotheken erkennen, welche User sich bei mir befinden. Google versichert zwar, dass diese Daten nicht zu Identifizierungszwecken missbraucht werden. Jedoch würde ich einem Unternehmen, welches mit dem Handeln von Daten sein Geld verdient nicht unbedingt trauen. Schließlich etablierten diese Firmen den Überwachungskapitalismus und präsentierten somit ihre Sicht auf unser Wertesystem. Auch ist es nicht mehr zwingend notwendig Cookies zu benutzen. Es gibt mittlerweile andere Konstrukte wie den LocalStorage oder SessionStorage. Selbst die Auflösung des Bildschirmes kann ein Identifikationsmerkmal sein, wenn man diese Informationen mit dem Rest der übertragenen Daten kombiniert.
Warum ist das so?
Jeder Browser ruft beim Ausführen der HTML-Seite die eingebundenen Ressourcen ab. D.h. eingebundene Ressourcen wie beispielsweise Schriftarten, Bibliotheken und IFRAMES werden durch den Browser heruntergeladen. Bevor der Browser aber anfängt, sagt er dem Webserver der Ressource von wo er kommt, welche Version der Browser hat und wie das Betriebssystem lautet. Natürlich sind auch noch weitere Informationen in der Anfrage enthalten. Aber die Grundlegenden Informationen zum System sind immer im User Agent verpackt.
Natürlich kann man diesen User-Agent-String auch manipulieren, aber welcher Standard-Benutzer macht das schon. Zum anderen werden auch andere Informationen übertragen, wie z.B. die IP-Adresse des Abfragenden. Hat man zuvor andere Seiten besucht, in denen Google auch vertreten ist, so kann man daraus eine Identifizierung vornehmen. Diese Informationen sind sozusagen der Fingerprint des Browsers. Benutzt man beispielsweise den Browser Tor, sollte man folglich niemals die Größe des Browserfensters anpassen. Somit geht man sozusagen im Grundrauschen des Internets unter, wenn nicht andere kompromittierende Versuche unternommen wurden, das Tor-Netzwerk zu manipulieren.
Wie funktionieren Cookies
Wenn wir eine neue Webseite abrufen, dann verfügt unser Browser über keine Information vom Server. Er kennt keine Bilder, Texte und Cookies. Dies ist die erste Sitzung! Der Server empfängt die Anfrage und sendet je nach Konfiguration ein neues Cookie und andere Informationen über den Header der Webseite. Im Header könnten auch Cacheeinstellungen oder Sicherheitskonfigurationen festgeschrieben werden. Aber in diesem Beitrag behandeln wir nur die Cookies.
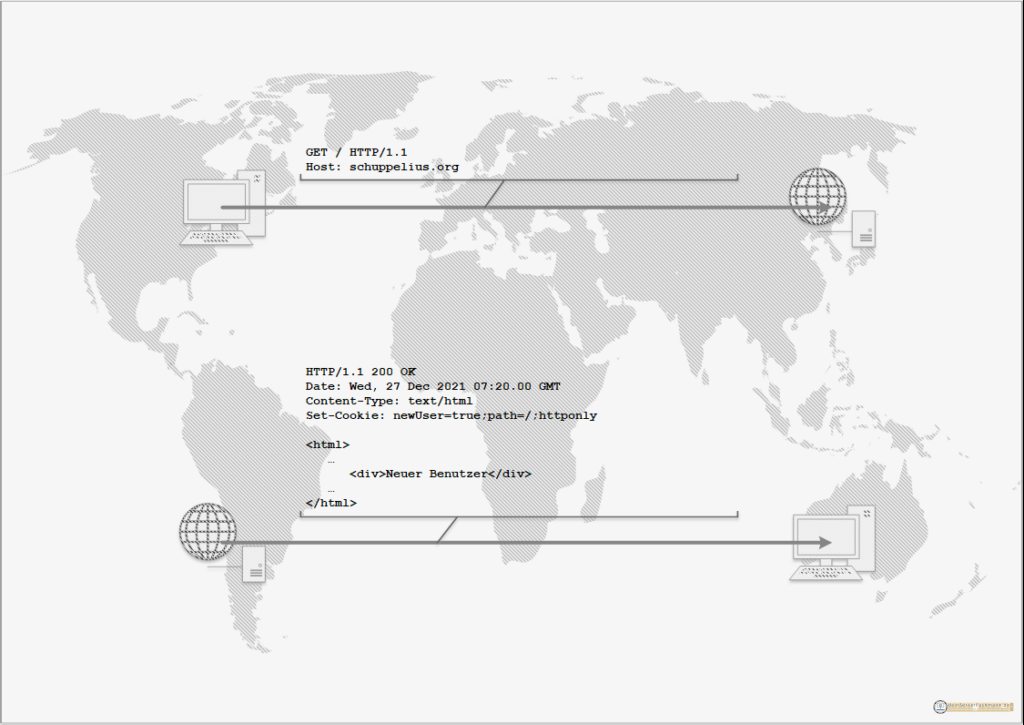
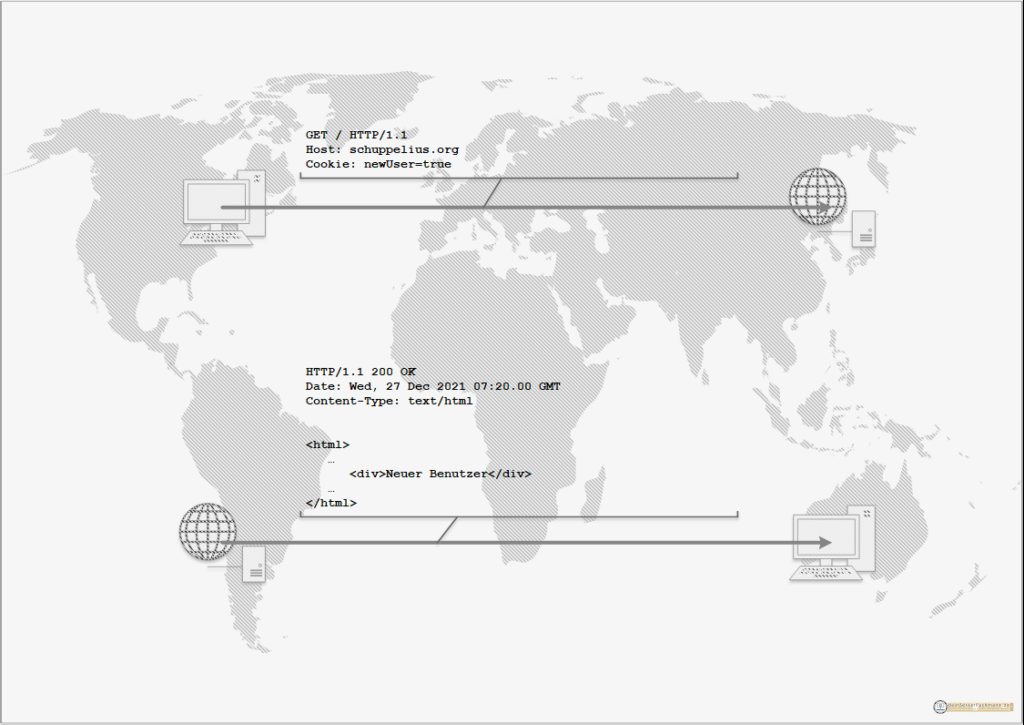
Dieses Cookie soll sozusagen bekannte Benutzer von unbekannten Benutzer trennen. Der Browser empfängt nun diese Daten und legt das Cookie im Speicher des Browsers ab. Fragen wir nun wiederholt die Webseite ab, sendet der Browser das zuvor empfangene Cookie an den Webserver und der Code der Seite kann diese Information nun in den HTML-Code einbauen. Da wir den Inhalt des Cookies nicht verändert haben. Wird die Webseite so ausgeliefert wie der Webseitenbetreiber es bei diesem Cookiewert vorgesehen hat. An sich hat sich bei unserer erneuten Abfrage nur die Senderichtung des Cookies geändert. Der HTML-Code der Webseite bleibt der Selbe, wie beim ersten Aufruf.
<a href="/register" onclick="document.cookie='newUser=false'">Fertig</a>
Nun klicken wir uns durch die Webseite und führen die mögliche Registrierung der Webseite durch. Nachdem wir alles eingetragen und auf den Button “Fertig” geklickt haben, setzt der Browser ein JavaScript in “Bewegung”. Dieses Skript hat nur eine Funktion und zwar ein Cookie mit dem Wert newUser=false zu setzen. Welches durch den ausgelösten Request an den Server übermittelt wird. Der Webserver ließt das Cookie aus und reagiert mit einer neuen Webseite.
Zugegeben, wer so von registrierten Benutzern unterscheidet, wird vermutlich schneller Opfer eines Angriffes als er schauen kann. Aber dieses Beispiel sollte euch auch nur die Technik hinter den Cookies veranschaulichen. In so einem Cookie kann, wie oben beschrieben, alles mögliche drin stehen. Wie und mit welchen Sicherheitsmechanismen die Cookies ausgewertet werden hängt vom Webseitenbetreiber ab. Manchmal lohnt es jedoch, mal einen Blick in die Cookies zu werfen. 😉 Fast jeder Browserhersteller hat so seine Entwicklertools, mit denen man etwas von der Webseite erfahren kann, welche man gerade besucht.